今天是對 deeplab 系列模型進行分享的最後一天了,要講的是 deeplabv3+,顧名思義是基於 deepLabv3 做出改進的語義分割架構
先來說說,deeplabv3+ 要來解決 deeplabv3 模型的一些議題,
在 deeplabv3 模型中,它在經過處理後的特徵圖的解析度上通常只會有原始輸入影像的 1/N,這導致了相當大的計算量,再來就是,deeplabv3 模型只簡單地使用雙線性插值上採樣,使得無法準確地還原出分割物體的細節
deeplabv3+ 將模型結構更改成 Encoder-Decoder 網路,也就是在 deeplabv3 的基礎上添加了一個編碼器(Encoder),這個編碼器的作用是解決上面提到的 deeplabv3 在處理高解析度影像時會耗時過多的問題,再來,為了生成更快速且強大的語義分割模型,deeplabv3+ 將深度可分離卷積(Depthwise Separable Convolution)應用於 ASPP 和解碼器模組,即應用深度可分離卷積來優化編碼器-解碼器網路
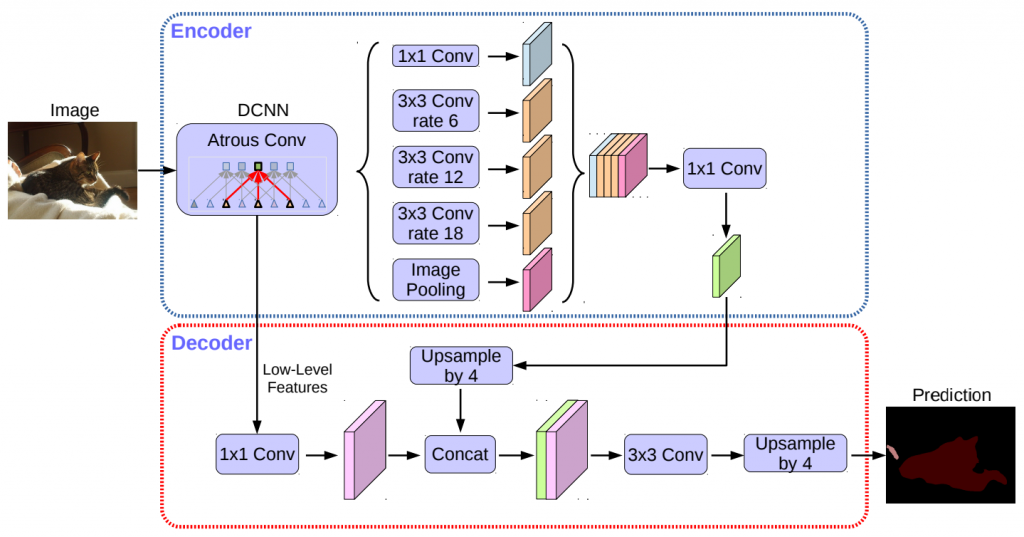
在 Encoder 部分,deeplabv3+ 使用主幹網路 DCNN,可以是 Xception,來提取基本特徵,接著,它使用空洞卷積從不同感受野的特徵圖中提取資訊,最後使用 1x1 的卷積層將它們混合在一起;在 Decoder 部分,是負責抽取主幹網路前面的特徵,這些特徵代表著細節資訊,首先會將由編碼器產生的低維度特徵圖進行上採樣,並使用 Concate 的方式將這些特徵圖混合在一起,最後,再經過 3x3 的卷積層和上採樣過程,產生出與輸入影像相同解析度的像素級別預測結果
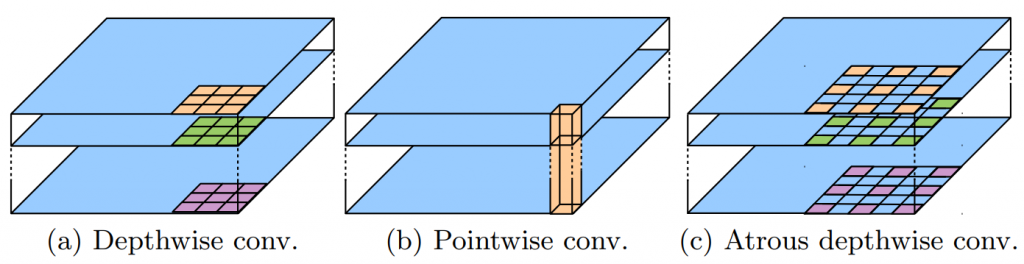
(a). 深度卷積(Depthwise Convolution): 對每個輸入通道套用單一濾波器
(b). 逐點卷積(Pointwise convolution): 即 1×1 卷積
(C). Atrous Depthwise Convolution: 在深度卷積中使用空洞卷積,這可以降低模型的計算複雜度,同時保持相似或更優越的性能
在 deeplabv3+ 中,它將所有的 max pooling 結構都替換成步長為 2 的深度可分離卷積,以進一步提高性能
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation

